


Arctype SQL: Write Faster and More Efficient SQL Queries
Strategies for Optimizing SQL Queries


Original published at: Arctype SQL
This article will explain why optimization is so important as we explore some of the best ways to quickly optimize your SQL queries for minimum impact on database performance through:
- Efficient indexing,
- SELECT and SELECT DISTINCT statement refinement,
- Strategic use of wildcards and conditionals, and
- Query cost analysis using EXPLAIN
Introduction to SQL Query and Data Management
Standard Query Language, or SQL for short, allows users access to databases using specific commands or queries, allowing them to change and maintain them. Commands such as SELECT—which helps users extract the data from the database—UPDATE, DELETE, INSERT INTO, and many more, make data management easier for database administrators.
Each of these commands has its own set of functionalities that are useful when working with databases. A few SQL IDEs, such as Arctype, offer developers the ideal framework for visualizing, designing, modeling, and managing their databases. Arctype is a free, collaborative, and intuitive SQL editor to simplify all your data management and visualization requirements.
In the subsequent sections, we will briefly discuss and identify factors that affect query performance and how we can improve each to get the same desired output with much faster queries.
The Three Phases of an SQL Query
From developing a global schema for our logical database to assigning data over a computer network to establishing local DBMS-specific schemas, the life-cycle of a database encompasses all of the phases required in database creation. The process does not stop because database monitoring, improvement, and maintenance begin only after the design is defined. A critical understanding of these phases not only helps us make better optimization decisions but also helps identify performance issues:
Annotation: Following the execution of a query, the SQL server parses the command using a parser, which analyzes the data and divides it into various data structures. This query is modified, and the result is a parse tree with explanation texts for all of the data inputted.
Query Optimization: After an SQL query is parsed, a query optimizer enables the SQL server to return the output more efficiently. The goal is to utilize system resources as efficiently as possible while also lowering costs (CPU and time). The optimized query is then sent on to the next phase:
Query Execution: This phase develops the mapped-out query plan into its final form. Following that, we get presented with an output.
Size = Resources: SQL Query Run-Time Theory
We often overlook the fact that databases, like all computer-based software, have hardware limits. In addition to hardware configurations, other factors influence the speed with which SQL server queries are handled. These factors include table size, how tables are joined, the number of queries running simultaneously, row combinations, and the database software and optimization itself.
Although a few of these factors, such as the database software, cannot be controlled, most can be. We will explore which are within our bound of control below.
How SQL Table Size Affects Performance
The number of rows in a query impacts how quickly it is processed. In other words, the larger the number of rows, the higher the probability of slow performance. Simply shrinking the size of the table by removing redundant data can easily remedy this issue.
We can start a series of analyses on a section of the data to speed up this redundancy-removing intermediate step but not before removing any constraints. Before executing this process, you implement it through the whole dataset. Additionally, it is important to ensure that our desired data is still in the final query.
However, speeding up the intermediate phase will cause the qualitative evaluation to slow, so another way to manage the size of a query-result table is by enforcing a LIMIT clause using Mode. While constructing and refining a query, we don’t necessarily need to traverse an entire dataset—all we typically need is 100 rows of sample data upon which we can test the logic, output, and formatting of our query.
While this may seem like a small dataset, it will return the output in a substantially shorter time. The trade-off? While employing the LIMIT clause can significantly speed up the process, it may not produce an accurate set of results. Thus, we should only use it to test the logic of a new query.
Correlation between SQL Table Joins and Query Runtime
The run time of an SQL query increases every time a table join is implemented. This is because joins increase the number of rows—and in many cases, columns—in the output. To rectify this situation, the size of the table should be reduced (as previously suggested) before joining.
Does LIMIT Work with SQL Aggregate Functions?
Aggregation is the combination of two or more rows. Unlike simply retrieving the rows from the dataset, combining two or more rows and then giving an accurate output requires more computing power and time.
While the LIMIT clause works well in situations where reducing the size of a table doesn’t fundamentally alter query results, it is ineffective with aggregations. When an SQL query performs aggregate functions on a dataset, the output is restricted to a predetermined number of rows. If you intend to combine the rows into one, using LIMIT 100 —for example— to minimize the runtime will not work.
What is SQL Query Optimization?
SQL query optimization is simply writing queries using a conscious approach. SQL is a declarative query language, meaning that it is simple to use and specifically intended to focus on the data that needs to be retrieved. Query optimization is often neglected during the development phase because the data tested is small. The consequences of this decision, however, become greatly pronounced once the project goes live and there is a constant influx of live data flooding the database. Ultimately, all roads lead back to the question: is there a better way to create SQL queries that run faster?
Strategies for Optimizing SQL Queries
To accomplish optimization, we must correctly handle indexing, avoid loops, and leverage the SELECT and EXITS() functions, subqueries, row selection, and wildcards. We will look at some of these practices below:
Using Indexing to Improve Data-Retrieval Time
An index is a data structure that improves the data retrieval speed on a database table and represents a simple yet effective way to polish our queries. Proper indexing ensures quicker access to the database, and a well-indexed database will have faster lookup times—ensuring that your application can find the specific data needed from the database more quickly.
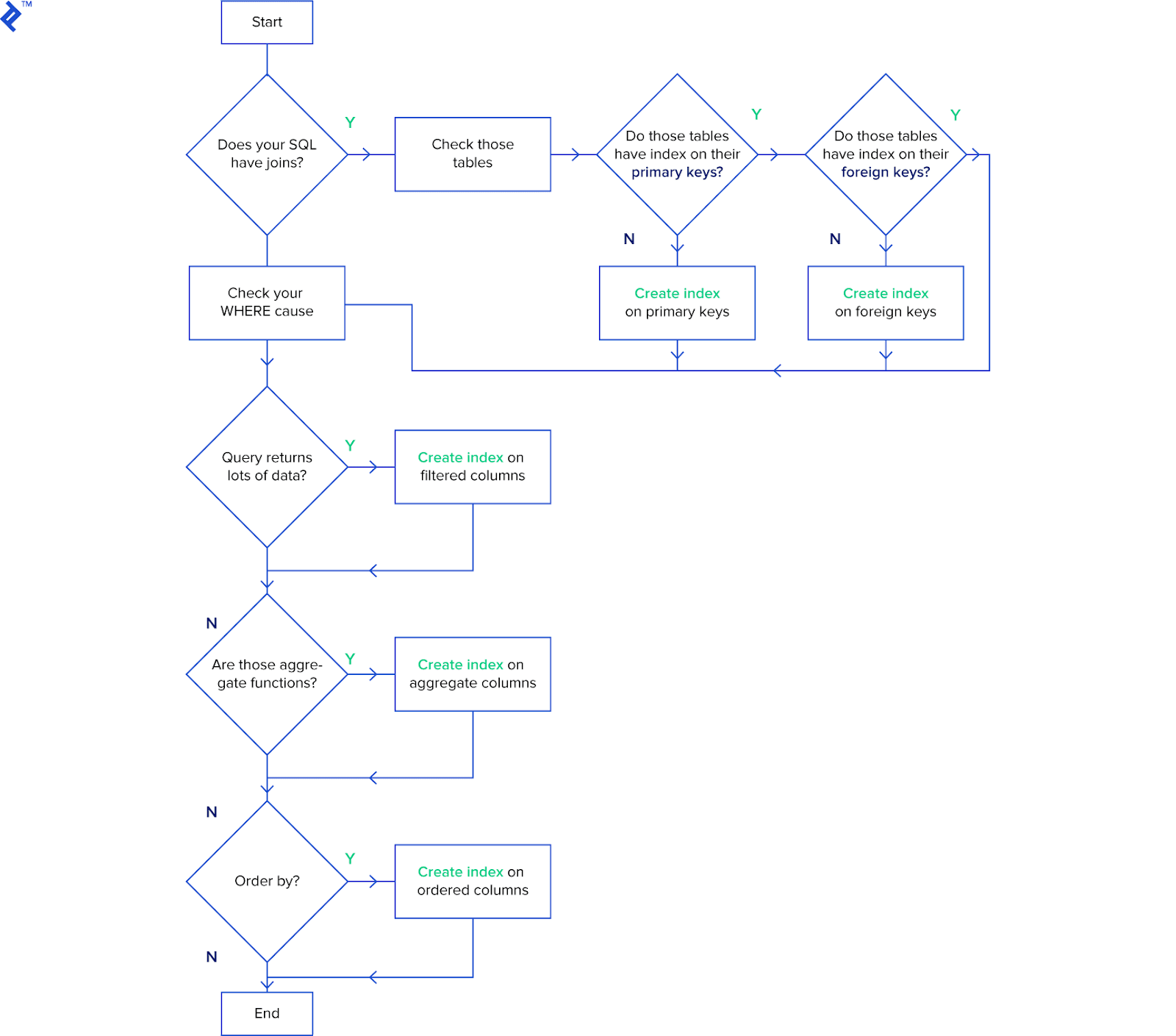
Above is a simple checklist to help effectively structure queries. Because all tables require a primary key, ensuring that our primary key has an index aids data retrieval. It, in turn, guarantees that all tables have a clustered index within them. Thus any retrieval operation from the table using the primary key will tend to be fast. However, regularly using ‘INSERT’ and ‘UPDATE’ to maintain our index logically leads to lower performances.
Which Is Better: SELECT Column or SELECT *?
We often tend to use SELECT when running exploratory queries. You can substantially improve performances by simply specifying the column required instead of using the to return all and transfer gigabytes of data across the network. Here is an example:
SELECT * FROM Games
A peek at the execution plans shows: Query cost as 1655.02 and Execution Time: 0:00:0.00377150
The problem with the above, however, is that you are processing more data than is actually necessary. It sounds simple, but even the most seasoned developers habitually make this mistake. A more efficient technique is to simply select the columns with which we are actually concerned:
SELECT Name, Year, Genre FROM Games
A peek at the execution plans shows: Query cost as 1655.02 and Execution Time: 0:00:0.00011700
Why You Should Avoid SELECT DISTINCT
We usually utilize the SQL DISTINCT clause whenever we want unique records from our query. Let’s say we merged two tables and got duplicate rows in the result. The DISTINCT operator, which filters the duplicated row, provides a simple workaround.
Now, let’s compare the execution plans for some simple SELECT statements. Note that the DISTINCT operator is the only difference between the queries:
SELECT Year FROM Games
A peek at the execution plans shows: Query cost as 1655.02 and Execution Time: 0:00:0.00131060
However, the DISTINCT will present:
SELECT DISTINCT Year FROM Games
A peek at the execution plans shows: Query cost as 1655.02 and Execution Time: 0:00:0.01145430
Effectively Using SQL Wildcards
Consider a scenario in which you need to find a name or a state. Wildcards can help you with that, however, as appealing as this may appear, it is wasteful because it will drastically reduce query performance.
When we use wildcard characters at the beginning of a query, the query optimizer may not use the suitable index. Thus, it is best to avoid using a wildcard character wherever possible in your search strings, since it compels your SQL query to do a full-table scan. When the dataset is enormous, additional system resources, such as I/O, CPU, and memory are required.
To better optimize your query, a postfix wildcard can be more effective:
SELECT
Name
FROM
Games
WHERE
Name LIKE '%Wii%'
A peek at the execution plans shows: Query cost as 1655.02 and Execution Time: 0:00:0.02328750
However, when we use wildcards correctly (like this):
SELECT
Name
FROM
Games
WHERE
Name LIKE 'Wii%'
A peek at the execution plans shows: Query cost as 1655.02 and Execution Time: 0:00:0.01539200
Such improvement is remarkable—especially in a dataset with only 15975 rows. Now, consider how much of a difference it can make when querying Big Data.
Optimizing SQL Conditional Statements
Simply put, when filtering a query based on a condition, WHERE statements are more efficient.
On the other hand, HAVING should be used when filtering an aggregated field.
Why You Should Use EXISTS() Instead of COUNT()
When trying to scan a table, using EXISTS() is more effective than COUNT(). While the latter scans the table and counts all entries matching our condition, EXISTS() exits once the criteria are met.
Besides these practices mentioned, there are a few other tips, such as avoiding using functions at RHS of an operator, which can help improve the performances and meet your business needs.
Analyze SQL Queries Using EXPLAIN
An execution plan is the sequence of operations that the database performs to run an SQL statement. The data type we want, indexes, and other factors all affect the performance of SQL queries, as we have already explained. The best way to keep track of what is going on with a query is to look at the execution plan (without running it).
You can start your query with EXPLAIN to see the execution strategy, which will allow you to experiment and determine the optimal solution for your statements.
It displays the cost (the greater the number, the longer the run time) and should be used as a guideline rather than an absolute measurement. To be explicit, you can alter your query and then run EXPLAIN to see whether the cost has gone up or down:
EXPLAIN
SELECT
*
FROM
Games
Query Plan: Query cost as 1655.02, rows: 15975 and Execution Time: 0:00:0.00039610
On its own, EXPLAIN does not provide detailed information on our output, as our statement is not executed. We will need to utilize the ANALYZE keyword, which runs the query, to get a more detailed result:
EXPLAIN ANALYZE
SELECT
*
FROM
Games
Query Plan: Table scan on Games (cost=1655.03 rows=15975) (actual time=0.059..12.778 rows=15972 loops=1)\n'
Why Is SQL Query Optimization Important?
The goal of query optimization is to minimize the response time of our queries by choosing the best execution strategy under resource constraints. You can achieve this by making deliberate, careful, and well-thought-out design decisions during the database development cycle. So why is this so important? First and foremost, faster and more effective query processing. The system will be able to service more queries in the same amount of time since each optimized request will use less time as compared with an unoptimized request. It helps when trying to prevent latency while maintaining a good user experience for your application. Good optimization practices also slow down the wear and tear on your hardware and allow your server to run more effectively (less memory usage). Ultimately, all these ensure a high-performance level and optimized system.
Conclusion
Query optimization is a task that we should not neglect—it helps to fine-tune the overall performance of the database system. Even with a robust infrastructure, inefficient queries can drain the production database resources, leading to latency and a decline in performance. Therefore, the first and most important step is to identify and follow best practices and strategies for improving the life-blood of any data-intensive project—database queries.